
In dit artikel gaan we aan de slag met een concrete vraag waar ieder hotel mee te maken heeft: “Hoe kunnen we bepalen welke reserveringen worden geannuleerd?”. Lege kamers leveren immers geen inkomsten op.
Om dit te voorkomen worden kamers overboekt. Te veel overboeken leidt ontevreden gasten, te weinig overboeken leidt tot ongebruikte kamers.
Door op voorhand te kunnen stellen welke reserveringen worden geannuleerd is het mogelijk om de juiste balans te vinden en daarmee een juiste bezetting van de kamers te garanderen.
Bij het schrijven van dit artikel is gebruik gemaakt van de dataset zoals beschreven in Hotel booking demand datasets.
Een korte uiteenzetting van de dataset:
“This data article describes two datasets with hotel demand data. One of the hotels (H1) is a resort hotel and the other is a city hotel (H2). Both datasets share the same structure, with 31 variables describing the 40,060 observations of H1 and 79,330 observations of H2. Each observation represents a hotel booking. Both datasets comprehend bookings due to arrive between the 1st of July of 2015 and the 31st of August 2017, including bookings that effectively arrived and bookings that were canceled. […]”
Ken de data
Voor we starten met de dataset is het goed om een gevoel te krijgen bij de data die we voorhanden hebben.
Als data-analist, of data-eigenaar ga je er vast van uit dat je de data al kent en dat deze geen verrassingen voor je heeft. Toch is het goed om altijd stil te staan bij de volgende vraagstukken:
- Heb ik gaten of lege waarden in mijn data? Zo ja, zijn deze logisch? Vul de gaten op met standaard waarden.
- Is mijn data logisch? Een logische check kan zijn “heb ik reserveringen met 0 volwassenen, 0 kinderen en 0 babies?” Dit zijn vreemde reserveringen en dienen te worden uitgesloten voor verdere analyse.

Ken de klanten
Voordat we gaan kijken naar de annuleringen is het goed om te weten wie de klanten zijn. Ondanks dat we al een goed beeld verwachten te hebben kan het geen kwaad hier toch even bij stil te staan.
Waar komen mijn gasten vandaan?
Het land van herkomst van de gasten kunnen we op meerdere manieren presenteren. Hieronder een tabel, gesorteerd op aantal reserveringen per land en een grafische visualisatie op de kaart, gekleurd naar aantal reserveringen.
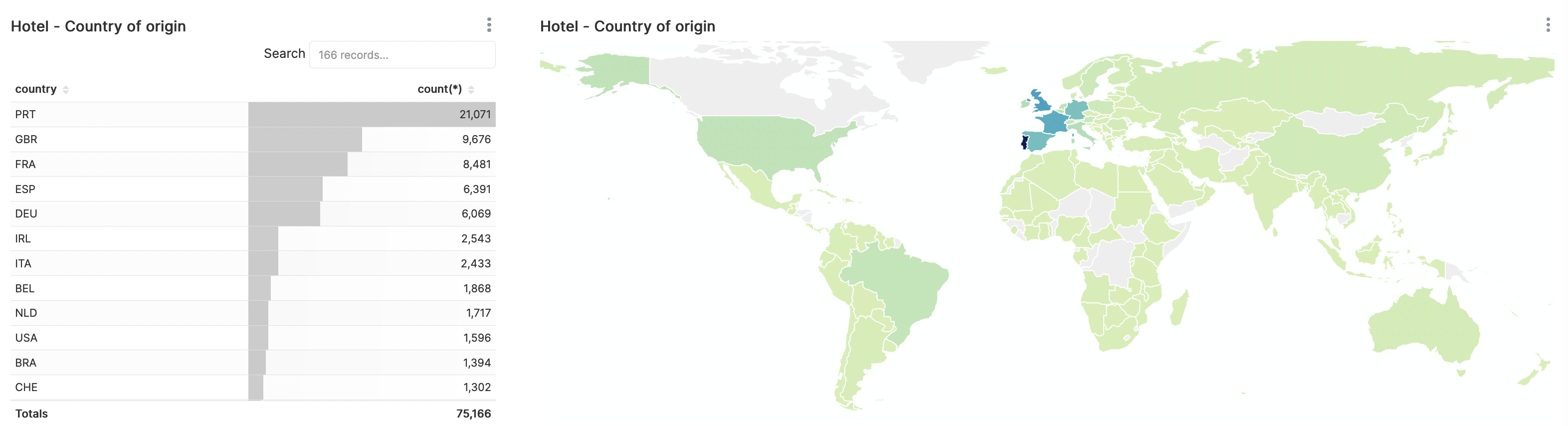
Zoals te zien komen gasten uit vrijwel de gehele wereld naar de hotels. Verreweg de meeste gasten komen echter uit Portugal en andere West-Europese landen.
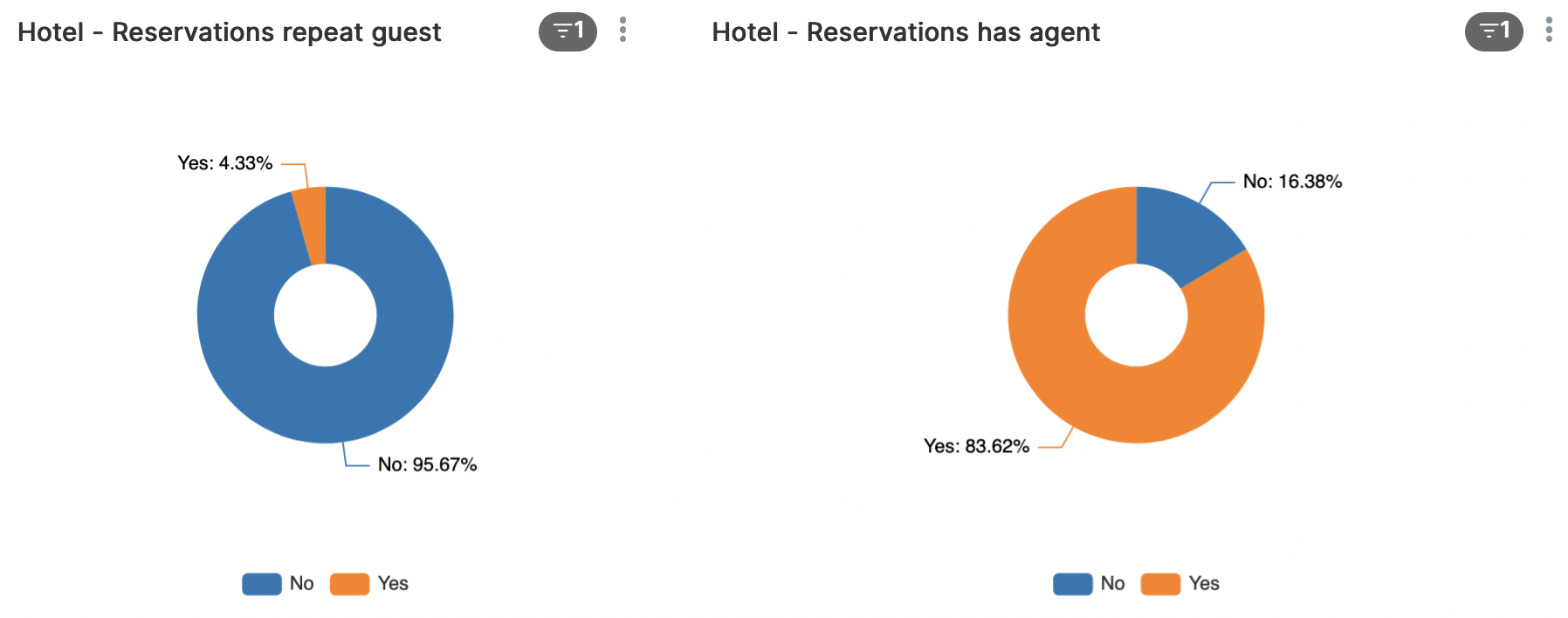
Hierboven zien we welk deel van de gasten terugkerend is en welk deel via een agent heeft geboekt.
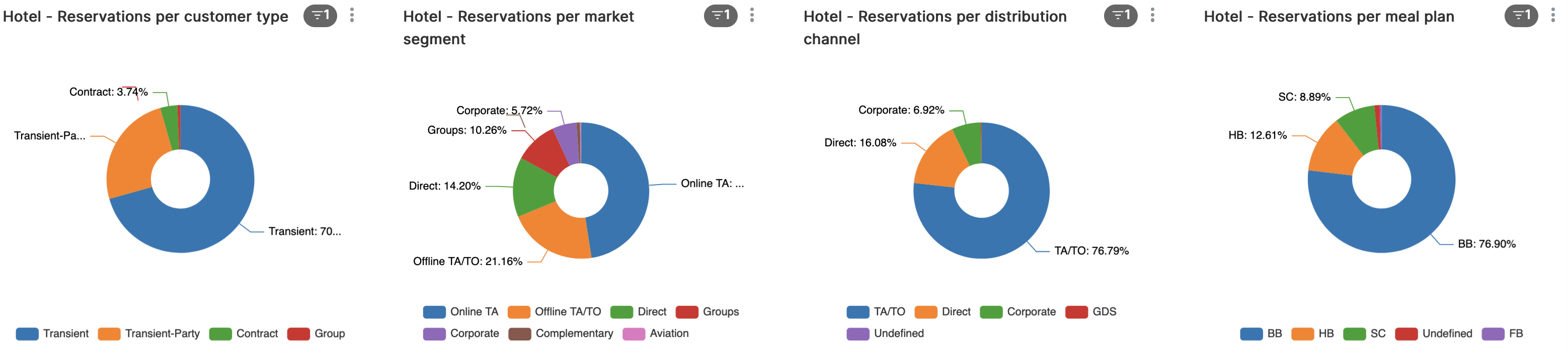
Verder zien we de klant-types, marktsegmenten, distributiekanalen en maaltijd-keuze.
Wat betalen de gasten per kamer per nacht?
Het is goed rekening te houden met het feit dat de prijzen tussen de hotels variëren, bijvoorbeeld doordat de hotels verschillende kamersoorten en ontbijt- of dinerarrangementen aanbieden. Ook seizoenspatronen spelen een rol.
Hieronder een voorbeeld van de gemiddelde kamerprijs (ADR) gepresenteerd per gereserveerd kamertype, uitgesplitst per soort hotel. Ook een weergave van de ADR per land van herkomst van de gast. Kunnen we hier nog interessante informatie uit halen?
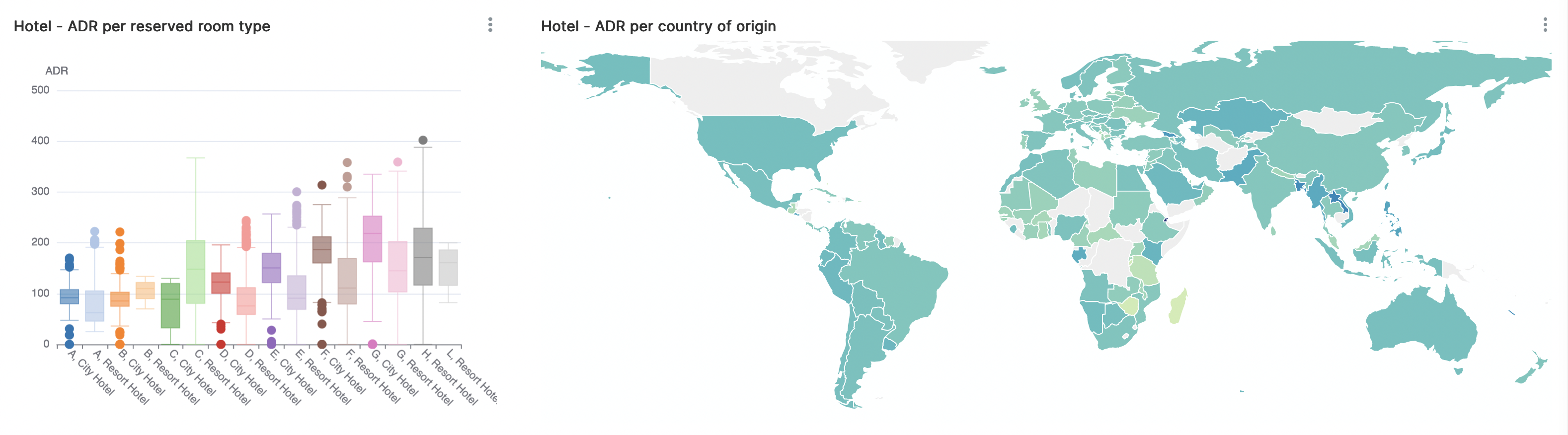
Zoals te zien hangt de ADR af per kamertype en de standaarddeviatie voor het specifieke kamertype.
Hoe verschilt de kamerpijs per nacht gedurende het jaar?
Door de ADR per reservering te analyseren is inzichtelijk te maken wat de ADR is per periode, plus hoe dit er uit ziet over de jaren heen.
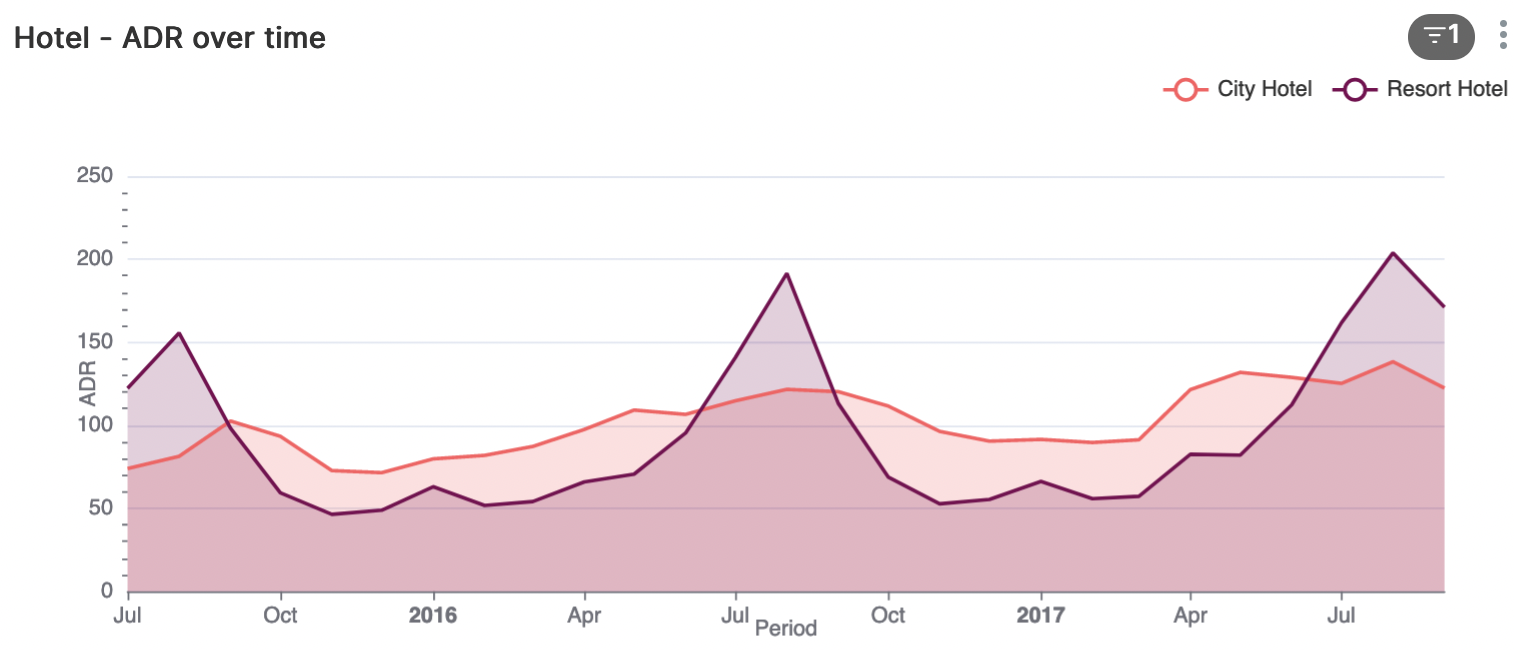
Zoals in deze visualisatie te zien is de ADR voor het city-hotel redelijk stabiel over het jaar heen. De ADR voor het resort-hotel kent grote pieken in de zomermaanden en zakt flink in de overige maanden van het jaar.
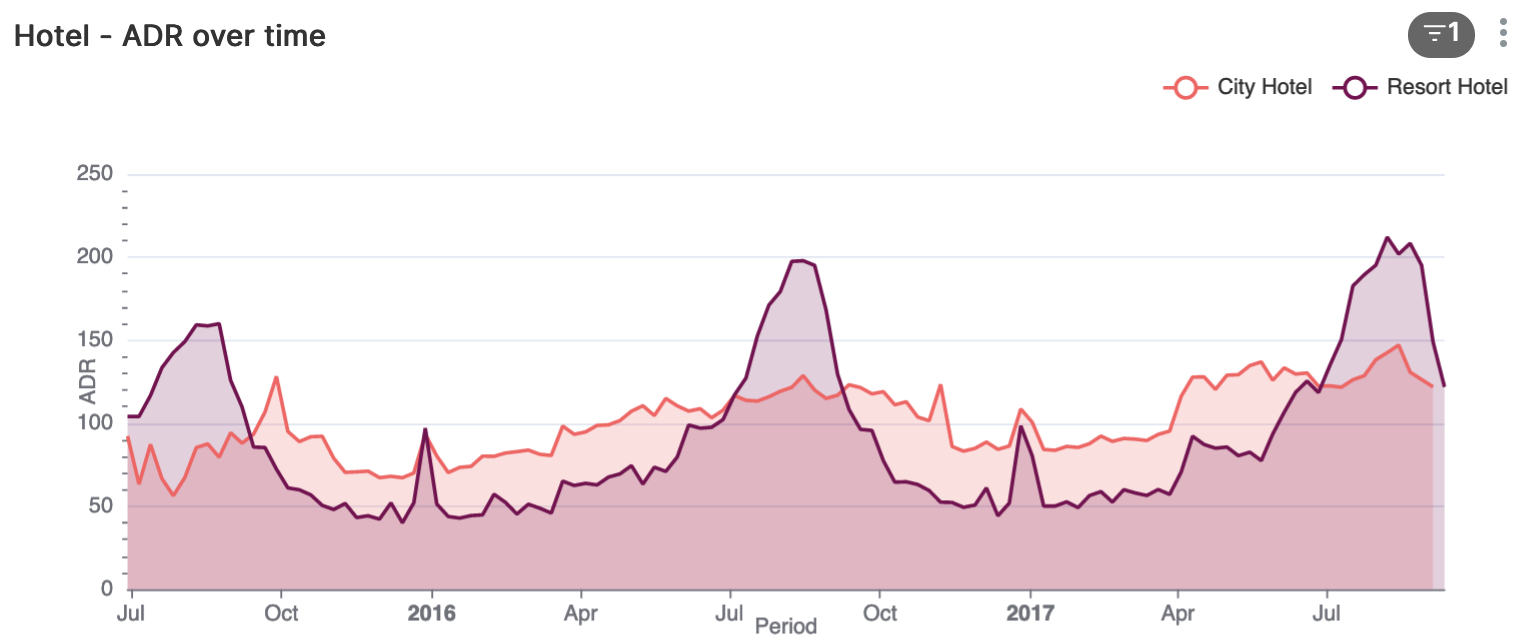
Wanneer we de granulariteit van de periode-as aanpassen van maand naar week dan zien we dat de ADR voor het resort-hotel rond de jaarwisseling een flinke piek kent.
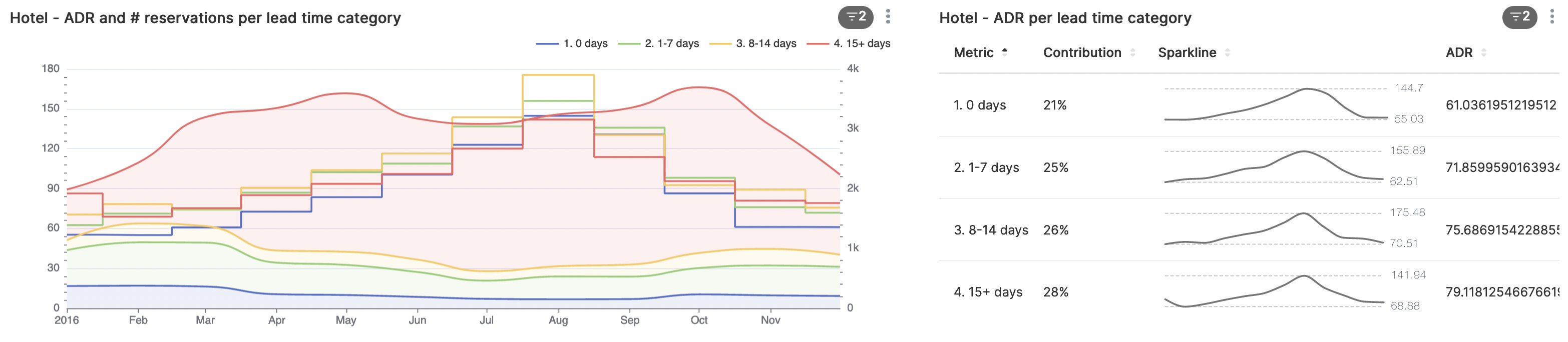
Als we kijken naar het aantal dagen tussen de reserverings- en aankomstdatum (de lead time) is te zien dat de ADR voor boekingen op de aankomstdatum zelf (lead time van 0 dagen) buiten de zomermaanden aanzienlijk lager ligt. Hier zie je duidelijk het effect terug van het verlagen van de prijzen om leegstand te voorkomen.
Verder zien we dat het voor gasten raadzaam is om voor de zomermaanden ruim van tevoren te reserveren om de laagste prijs te garanderen. In de rest van het jaar kan het interessant zijn een eerdere reservering te annuleren en opnieuw te boeken om een lagere prijs te bemachtigen.
Wat zijn de drukste maanden?
Inzicht in het aantal bezoekers aan de hotels is van belang om te zien waar de meeste druk ligt en de meeste behoefte is aan personeel.
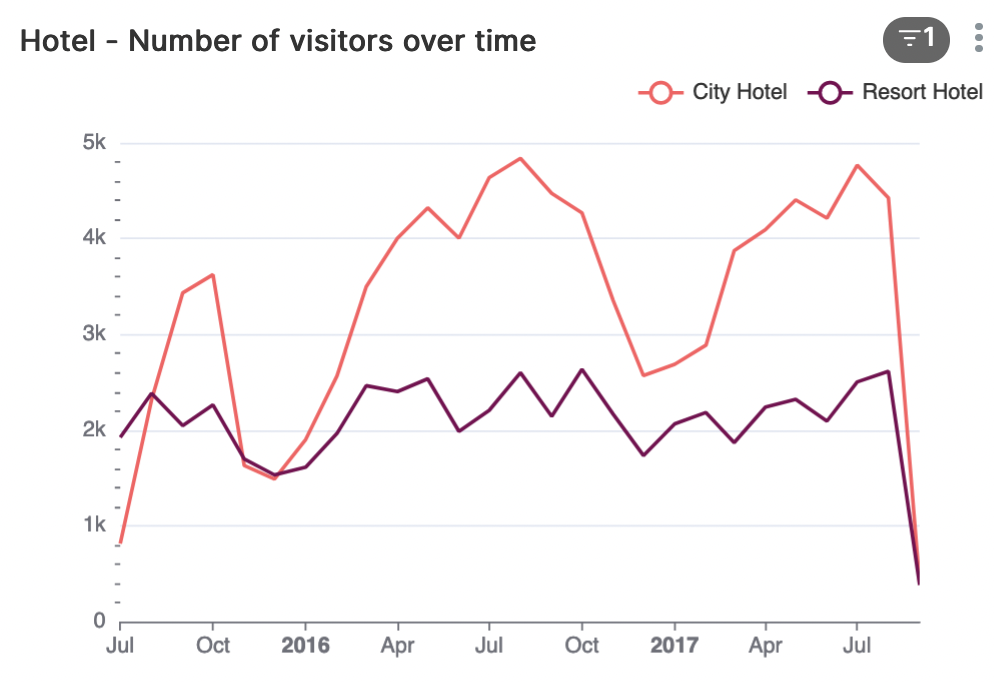
Als we kijken naar het aantal personen in-house dan valt op dat het city-hotel in de lente en herfst de meeste gasten heeft, wanneer de prijzen ook hoog zijn.
Voor het resort-hotel daalt het aantal gasten van juni tot september, precies wanneer de prijzen hoog zijn.
Beide hotels kennen het laagst aantal gasten in de winter.

Afgezet naar de dagen in het jaar zijn de piekmomenten op de data goed zichtbaar.
Hoe lang verblijven mijn gasten?
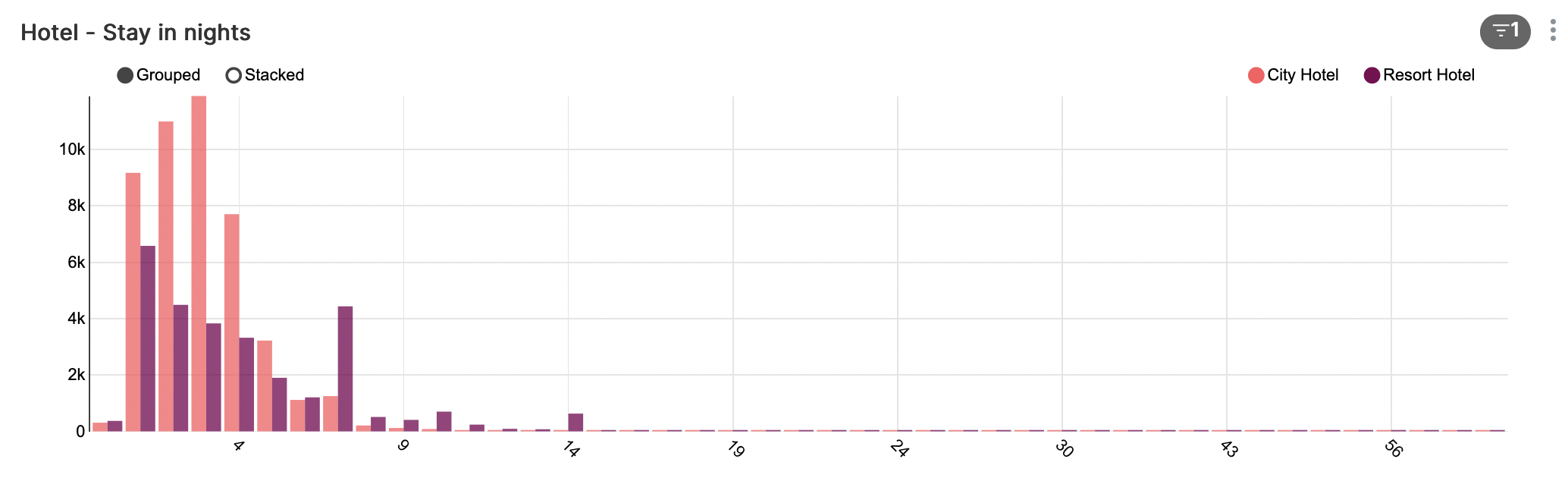
Zoals te zien kent het resort-hotel gemiddeld een langere verblijfsduur, daar waar het city-hotel meer (maar kortere) verblijven kent. Opvallende pieken voor verblijven van 7, dan wel 14 dagen in het resort-hotel.
Langere verblijven (tot 60+ dagen) komen voor, maar zeer zelden.
Welke gasten annuleren?
Om een beeld te krijgen van de annuleringen is het goed om te kijken naar een aantal zaken zoals het land van herkomst van de gast, klant-type, marktsegment, etc.
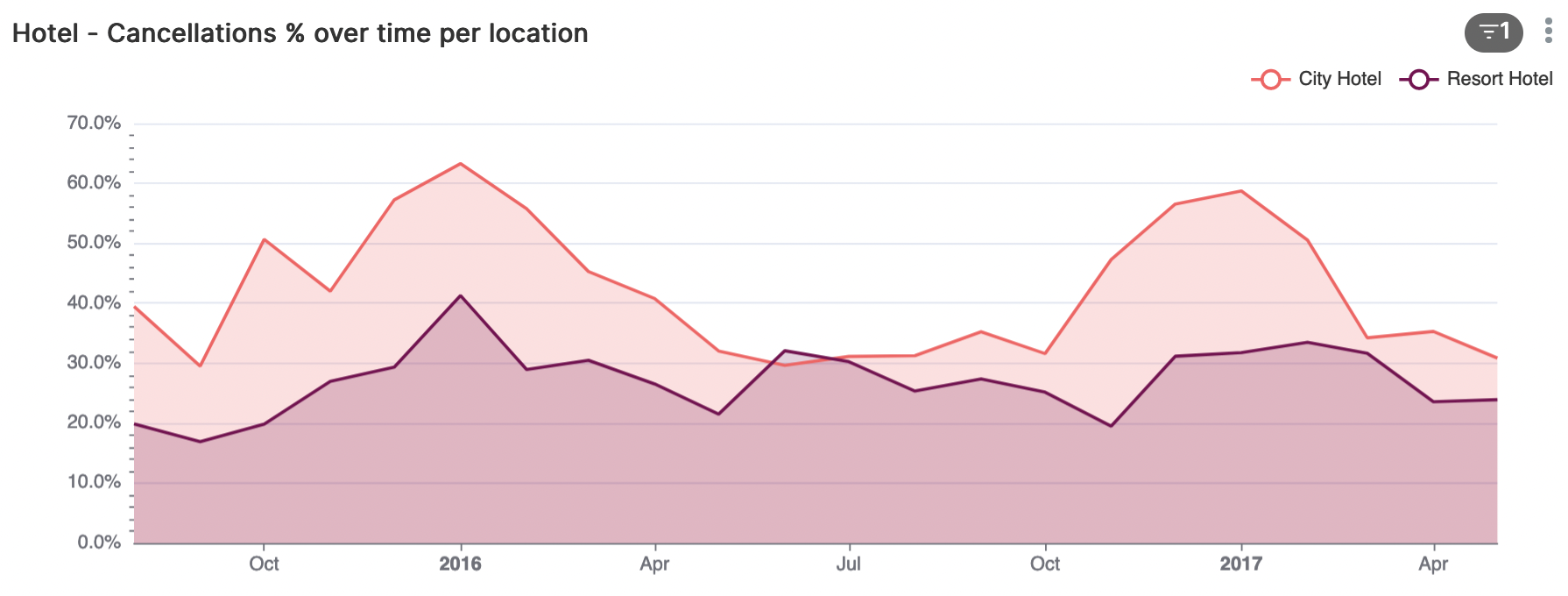
Zoals we hierboven kunnen zien kent het City-Hotel een relatief hoger aantal annuleringen dan het Resort-hotel, met met name pieken in de wintermaanden. Het resort-hotel kent een meer stabiel patroon van annuleringen.
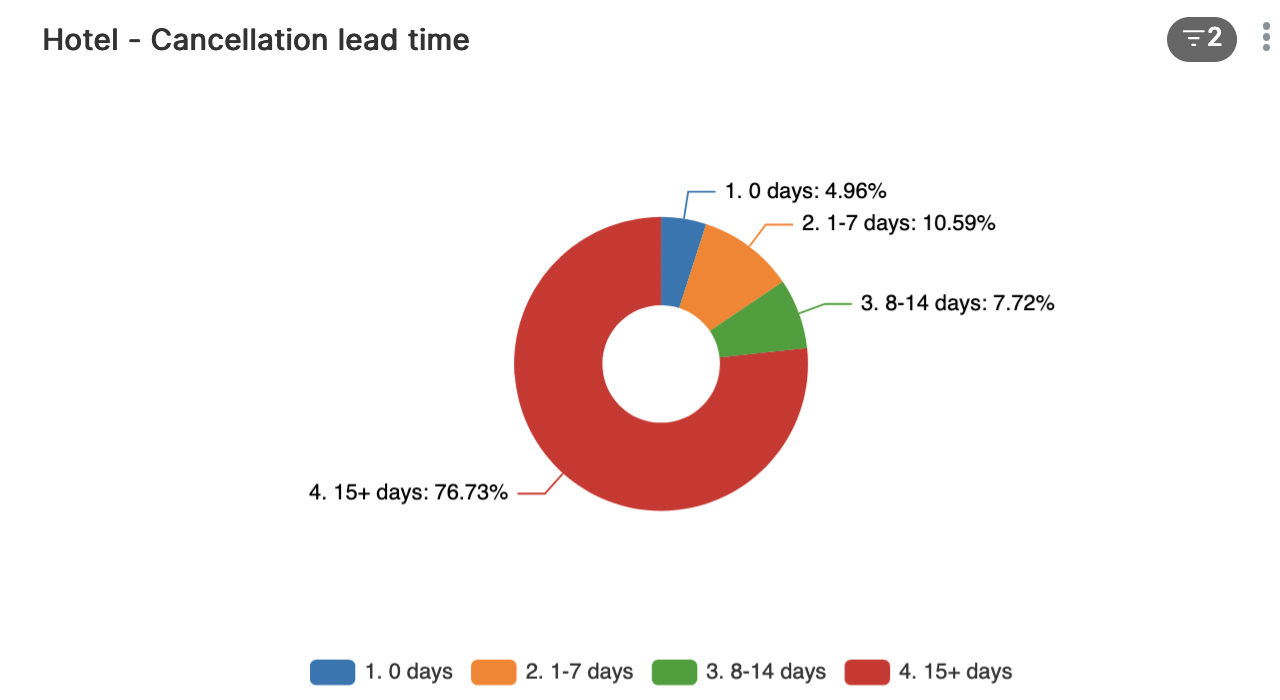
Het merendeel van de annuleringen komt 15 dagen of meer voor de geplande aankomstdatum binnen. Een kleine 5% wordt op de dag zelf geannuleerd.
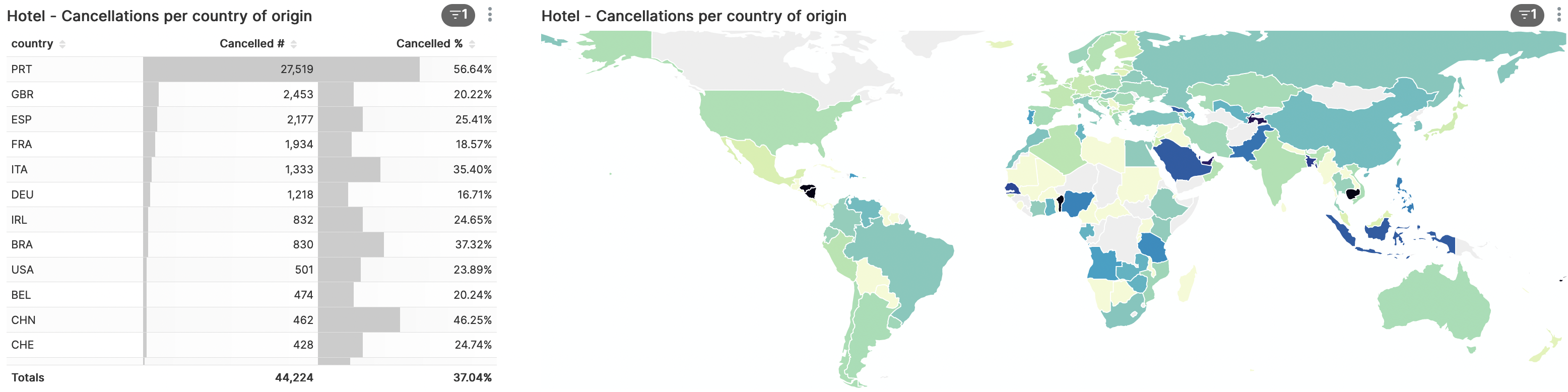
Zetten we het aantal absolute en relatieve annuleringen af per land van herkomst dan geeft dit een interessant beeld. De donkergekleurde landen kennen het relatief hoogst aantal annuleringen.
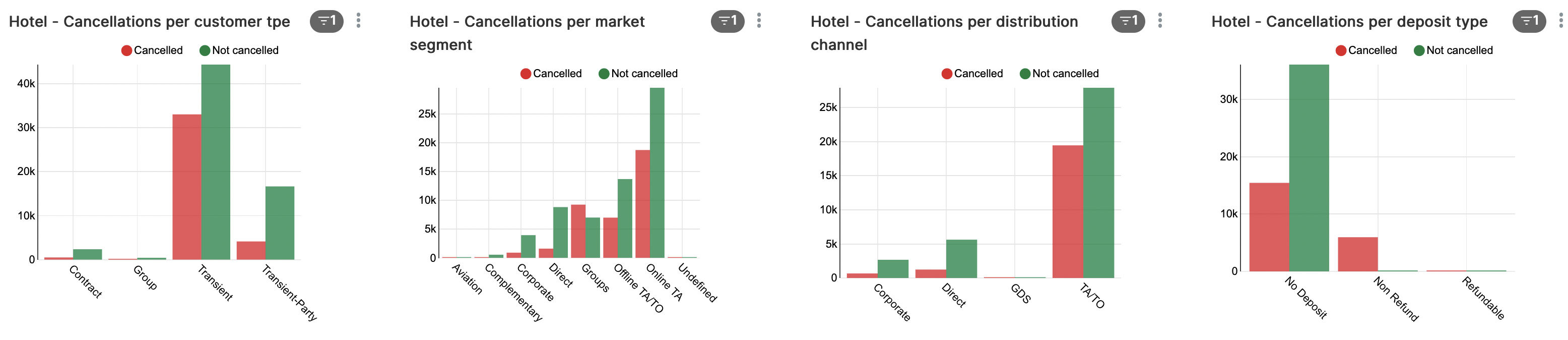
Wanneer we kijken naar het aantal reserveringen per klant-type, marktsegment en distributiekanaal worden zaken verder duidelijk. Vooral marktsegment ‘Groups’ (tweede grafiek) springt er hier uit, met meer annuleringen dan reserveringen die daadwerkelijk door zijn gegaan.
Klaarzetten van de data
Nu we een beeld hebben van de inhoud en betekenis van de data kunnen we bekijken hoe deze kan worden ingezet voor het doen van voorspellingen.
We zijn op zoek naar het antwoord op de vraag welke reserveringen zullen worden geannuleerd. Om te starten gaan we kijken naar de bestaande correlaties tussen de kenmerken van de reservering en de uitkomst, namelijk een annulering, vastgelegd in de kolom ‘is_canceled”.
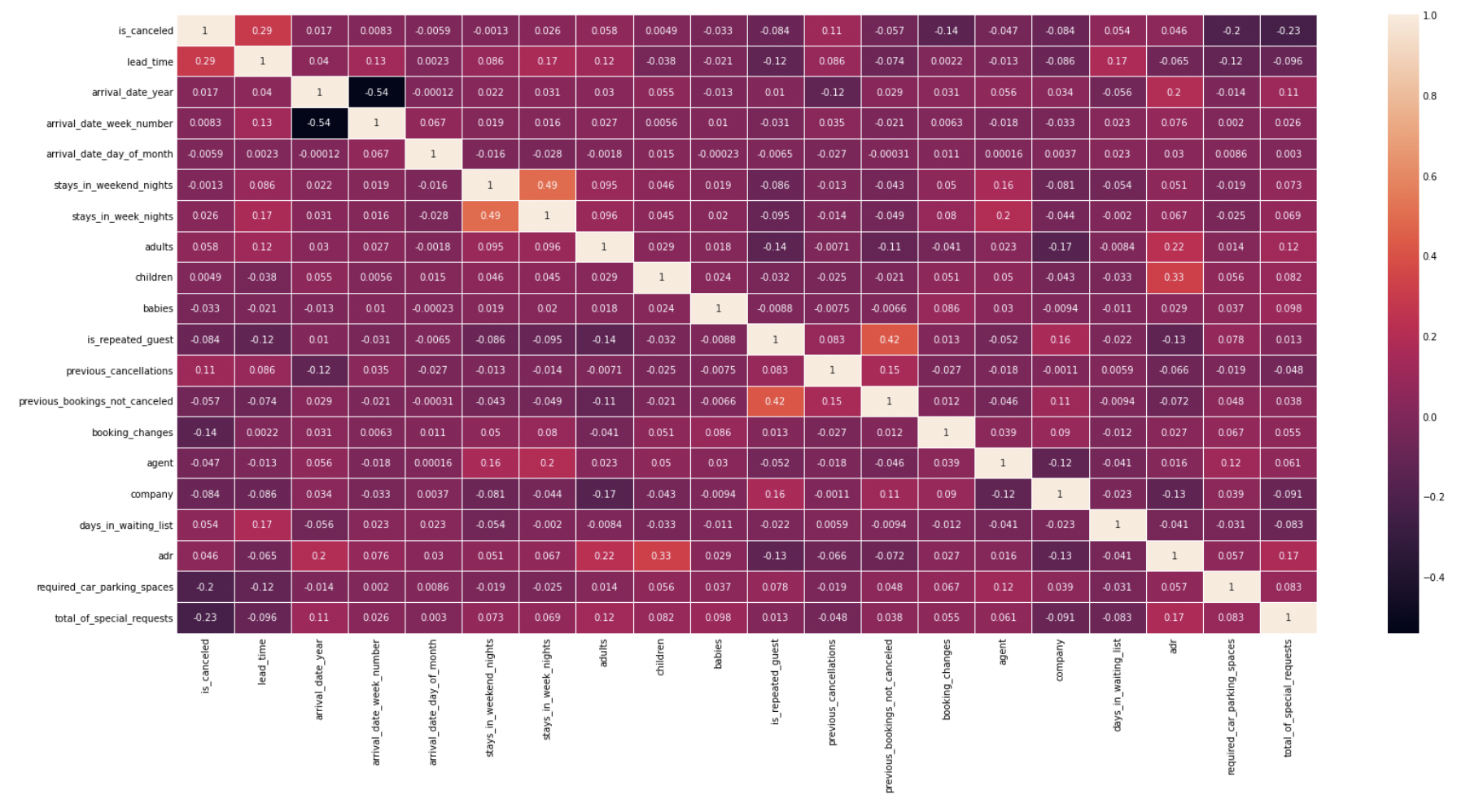
Op basis van dit overzicht weten we welke velden relevant zijn, maar ook welke velden niet relevant – en dus uit de set kunnen worden verwijderd. Interessant om te zien is dat bijvoorbeeld het veld ‘country’ niet relevant blijkt te zijn.
- days_in_waiting_list
- arrival_date_year
- assigned_room_type
- booking_changes
- reservation_status
- country
Het is van belang om de overgebleven dataset in te richten naar numerieke en categoriale data. Dit houdt in dat bijvoorbeeld marktsegmenten of kamertypes worden vertaald van een tekstuele waarde naar een categorie [0, 1, 2, ..]. Voor numerieke data zoals lead time, aantal volwassenen, ADR, eerdere annuleringen door de klant wordt de data genormaliseerd zodat deze door de computer te begrijpen is.
Hieronder een overzicht van hoe de verschillende numerieke waarden zich tot elkaar verhouden, gekleurd per uitkomst: geannuleerd in oranje, of niet geannuleerd in blauw.
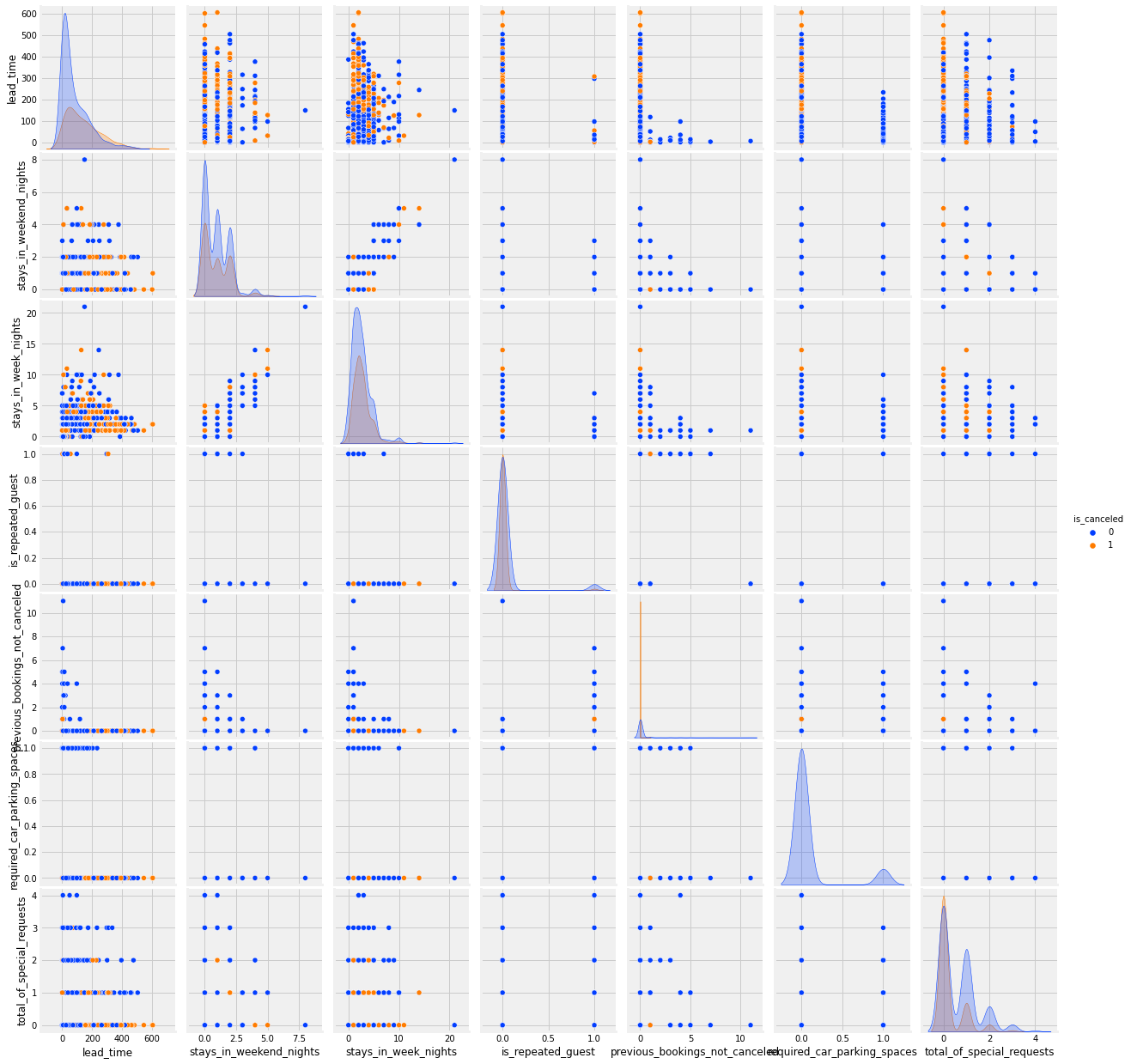
Het wordt niet direct duidelijk welke waarden met elkaar in relatie zijn. Wel is interessant dat de hoge ‘lead-time‘ (bovenste rij) tot annuleringen lijkt te leiden.
De resulterende gecategoriseerde en genormaliseerde dataset wordt nu opgeknipt in twee delen:
- Een deel met alle kenmerken in verschillende kolommen
- Een deel met de uitkomst, geannuleerd 1 of 0
Het resultaat wordt nogmaals opgeknipt in twee delen:
- Het deel wat dient te worden gebruikt om het model te trainen. Bij het trainen van het model wordt gekeken naar welke velden op welke wijze betrekking hebben op de uitkomst waarnaar we op zoek zijn. Hiervoor wordt een groot deel van de beschikbare dataset ingezet, in dit geval kiezen we voor 70% van de rijen.
- Het deel wat dient te worden gebruikt om de uitkomst van het model te valideren. Bij het valideren wordt gecontroleerd in hoeverre de uitkomst van het getrainde model overeenkomt met de werkelijk uitkomst. De validatieset bestaat uit het restant van de dataset, in dit geval 30% van de rijen.
Opstellen van het model
Er zijn vele verschillende soorten machine learning modellen. Het kiezen van het juiste model hangt af van de gewenste toepassing van de data.
Om een beeld te krijgen van de geschiktheid van het soort model op onze dataset is een aantal modellen getraind en houden we bij wat de uitkomst is per model op het gebied van precisie. Klik op de naam van het model voor een link met meer informatie.
| Soort model | Precisie |
|---|---|
| Cat Boost Classifier | 99,5694% |
| Artificial Neural network | 99,2115% |
| XgBoost Classifier | 98,4761% |
| LGBM Classifier | 96,7984% |
| Random Forest Classifier | 95,1934% |
| Decision Tree Classifier | 94,7124% |
| Ada Boost Classifier | 94,6117% |
| Gradient Boosting Classifier | 90,1155% |
| K-Nearest Neighbour | 89,3521% |
| Logistic regression | 81,0922% |
We kunnen concluderen dat op deze dataset de Cat Boost met 99,57% zekerheid kan voorspellen of een reserving wordt geannuleerd.
De tweede plaats wordt behaald door het Artificial Neural Network met een score van 99,21% zekerheid.
Een vaak toegepaste methodiek, de Logistic Regression blijkt het minst bruikbaar met een precisie van 81,09%.
Wanneer we kijken naar de ‘Feature importance’ van het Cat Boost model dan krijgen we een beeld van de invloed van de diverse kenmerken op de uitkomst geannuleerd of niet.
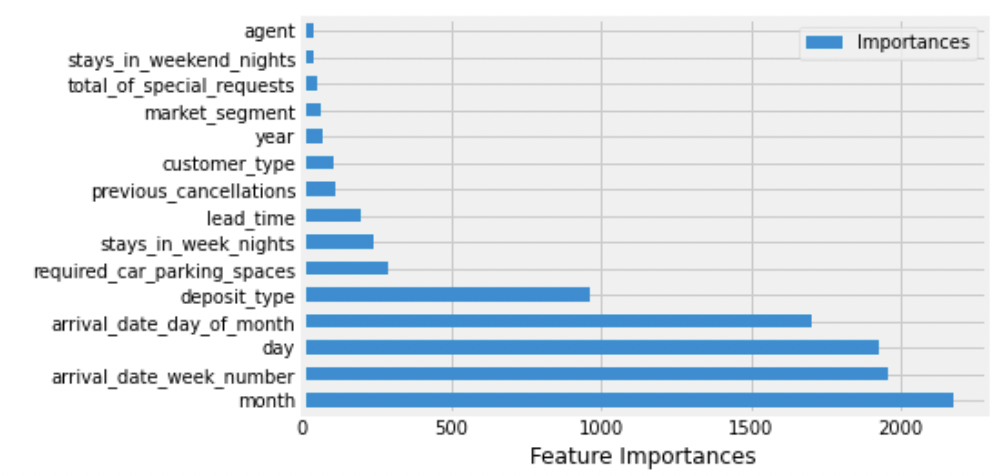
Hieruit kunnen we opmaken dat een aantal kenmerken buiten de beïnvloedingssfeer vallen, namelijk zaken gerelateerd aan de aankomstdatum. Daarnaast zijn er een aantal kenmerken waar wel mee te sturen valt, zoals de ‘deposit_type‘ en in meer of mindere mate de ‘lead_time‘.
Conclusie
Vanuit de verkenning van de data vallen een aantal zaken op:
- De meeste boekingen worden gedaan in het City-hotel. Dit hotel kent relatief het hoogste aantal annuleringen.
- Het hoge aantal annuleringen komt deels voort uit het niet toepassen van aanbetalingen.
- De meeste gasten komen uit West-Europa. Het is raadzaam om op deze regio in te zetten om hier het aantal annuleringen terug te dringen.
- We kennen een relatief laag aantal terugkerende gasten (City-hotel 3,44% en Resort-hotel 5,76%).
- Boekingen die worden gedaan zonder agent kennen een lager aantal annuleringen dan met agent (24,66% tegen 39,00%).
We kunnen de volgende zaken aanraden om de impact van de annuleringen te beperken:
- Zorg ervoor dat bij reserveringen aanbetalingen worden gedaan, bij voorkeur non-refundable. Zorg voor een strikte annuleringsprocedure.
- Zet in op terugkerende gasten, deze zijn minder geneigd te annuleren.
- Zorg voor meer directe reserveringen, bijvoorbeeld door kortingen aan te bieden.
- Let goed op waar de annuleringen plaatsvinden, is dit een specifiek marktsegment, distributiekanaal, agent, etc. en benader deze groep gericht.
- De zomerperiode kent relatief gezien de hoogste prijzen, dit is de periode waarin het voorkomen van annuleringen het meeste effect kent.
Meer info?
Meer weten, of behoefte aan demo van de gebruikte technieken in dit artikel, vul dan het Contactformulier in en er wordt contact met je opgenomen.